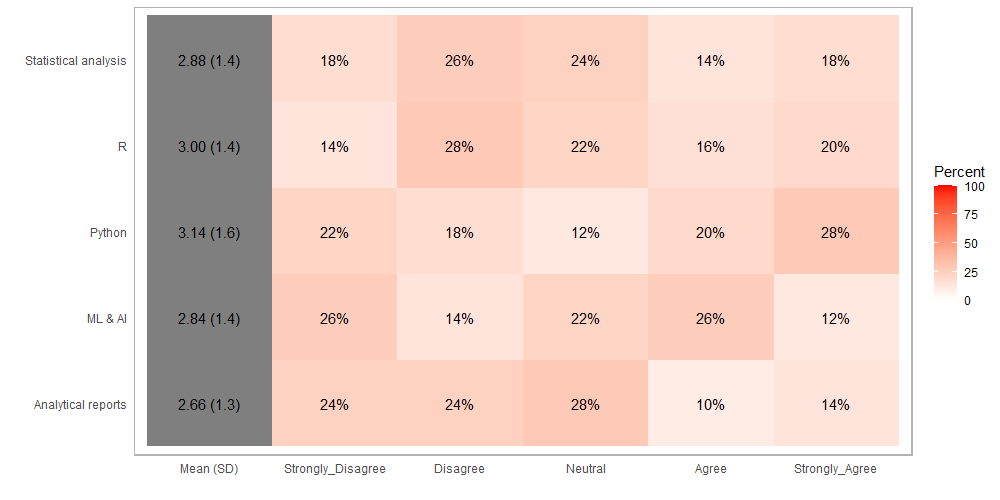
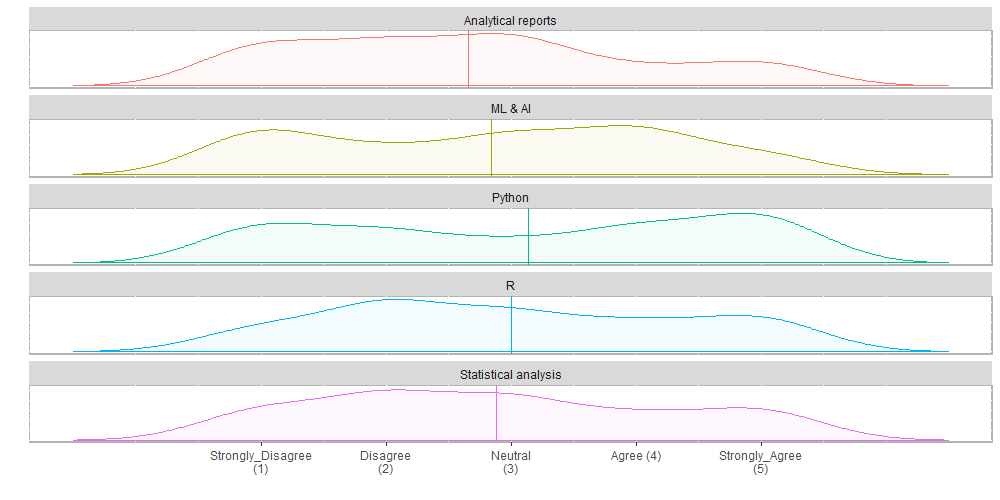
أحد تطبيقات البرنامج الاحصائي R هو عرض البيانات بإستخدام الرسوم البيانية (charts). في هذا الموضوع سوف نوضح بالأمثلة كيف يتم ذلك.
مثال(1): جمع أحد مطاعم الوجبات السريعة إستطلاع العملاء حول جودة الخدمة المقدمة لهم في المطعم وكانت النتيجة كما يلي:
| ممتاز |
جيد |
مقبول |
سيئ |
سيئ جداً |
| 15 |
37 |
13 |
7 |
4 |
اولاً نقوم بإدخال البيانات كما يلي:
In:
Ranking=c("ممتاز","جيد","مقبول","سيئ","سيئ جداً")
Numbers=c(15,37,13,7,4)
لتمثيل البيانات بواسطة الرسم البياني الدائري (pie chart) نستخدم الأمر التالي:
In:
pie(Numbers,main="إستطلاع العملاء حول جودة الخدمة",radius = 1,lab=Ranking, col=c("yellow","orange","red","green","blue"))
حيث تم إستخدام الأمر pie والذي يتضمن خيارات عديدة مثل: main وهو يمثل العنوان الرئيسي، radius ويمثل نصف قطر الدائرة، lab وهو يمثل مسميات القطاعات و col يمثل الوان القطاعات. بعد تنفيذ هذا الامر تكون النتيجة كما يلي:

لمعرفة مسميات الألوان، يمكن إستخدام الأمر التالي:
In:
colors()
كما يمكن يمكن التغيير قي الكود السابق كما يلي:
In:
pie(Numbers,main="إستطلاع العملاء حول جودة الخدمة",lab="",radius = 1,col=c("yellow","orange","red","green","blue"))
legend(x=-3,y=1,Ranking,cex=.8,bty="n",fill=c("yellow","orange","red","green","blue"))
حيث تم حذف المسميات وإستخدام أمر legend للحصول على مفتاح الرسم، وبالتالي أصبح الرسم البياني كما يلي:
 لاستخدام الرسم البياني الدائري ثلاثي الأبعاد (3D pie chart) نقوم بتحميل وتفعيل الحزمة التالية:
لاستخدام الرسم البياني الدائري ثلاثي الأبعاد (3D pie chart) نقوم بتحميل وتفعيل الحزمة التالية:
In:
install.packages("plotrix")
library(plotrix)
ثم بعد ذلك نستخدم الكود التالي:
In:
pie3D(Numbers,main="إستطلاع العملاء حول جودة الخدمة",radius=1,labels=Ranking, col=c("yellow","orange","red","green","blue"),explode=0.1,labelcex=0.8)
وبالتالي سوف تكون النتيجة كما في الشكل:

كذلك يمكن عرض هذه البيانات بإستخدام الأعمدة البيانية (bar chart) بإستخدام الكود التالي:
In:
barplot(Numbers,main="إستطلاع العملاء حول جودة الخدمة",names.arg=Ranking, col=c("yellow","orange","red","green","blue"))
حيث تم إستخدام الأمر barplot والذي يتضمن عدد من الخيارات للتحكم في الرسم وكانت النتيجة كما في الشكل التالي:
 كذلك يمكن إستخدام الكود التالي:
كذلك يمكن إستخدام الكود التالي:
In:
barplot(Numbers,main="إستطلاع العملاء حول جودة الخدمة",names.arg=Ranking, col=c("yellow","orange","red","green","blue"),cex.names=.5,horiz=TRUE)
حيث تم إستخدام الخيار (horiz=TRUE) لتحويل الأعمدة البيانية من الوضع الراسي الى الأفقي كما في الشكل التالي:
 كذلك يمكن استخدام الدالة barp المتوفرة ضمن الحزمة plotrix كما يلي:
كذلك يمكن استخدام الدالة barp المتوفرة ضمن الحزمة plotrix كما يلي:
In:
barp(Numbers,main="إستطلاع العملاء حول جودة الخدمة",names.arg=Ranking, col=c("blue"),cylindrical=TRUE, shadow=TRUE,border=FALSE)

مثال(2): كان عدد الطلاب المقبولين في أحدى الكليات خلال 5 سنوات على النحو التالي:
| 2014 |
2015 |
2016 |
2017 |
2018 |
| 702 |
650 |
585 |
740 |
810 |
بعد إدخال البيانات كما يلي:
In:
years=c(2014,2015,2016,2017,2018)
Numbers=c(702,650,585,740,810)
سوف نقوم بتمثيل هذه البيانات بإستخدام الرسم البياني الخطي بإستخدام الكود التالي:
In:
plot(years,Numbers,type="l",col="red")

أو بإستخدام الكود التالي:
In:
plot(years,Numbers,type="b",col="red")

يتضمن الأمر plot الخيار (type) والذي يمكن أن يأخد القيم الموضحة في الجدول أدناه:
| النوع (type) |
الوصف |
| p |
نقاط |
| l |
خطوط مستقيمة |
| h |
خطوط راسية |
| b |
نقاط تصل بينها خطوط مستقيمة |
| s |
خطوط مدرجة |
| S |
خطوط مدرجة |
| o |
نقاط وخطوط مستقيمة |
| n |
بدون نقاط او خطوط |
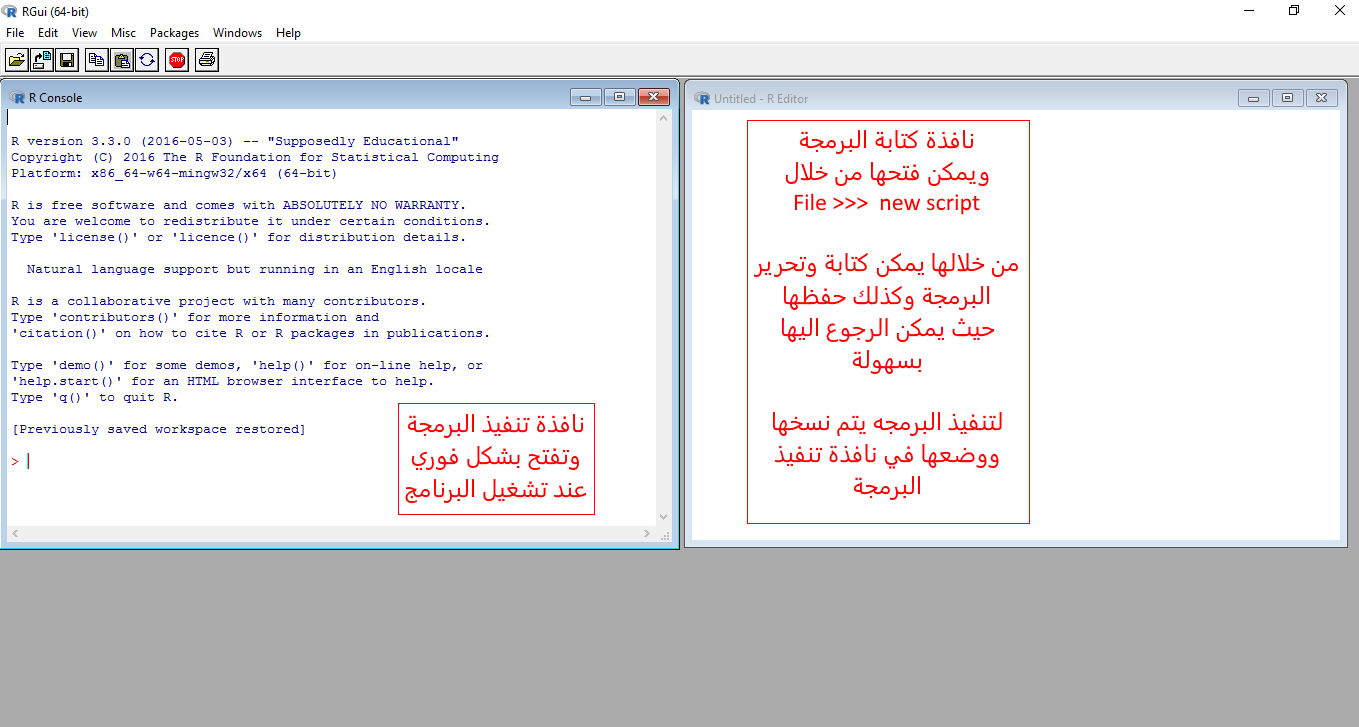



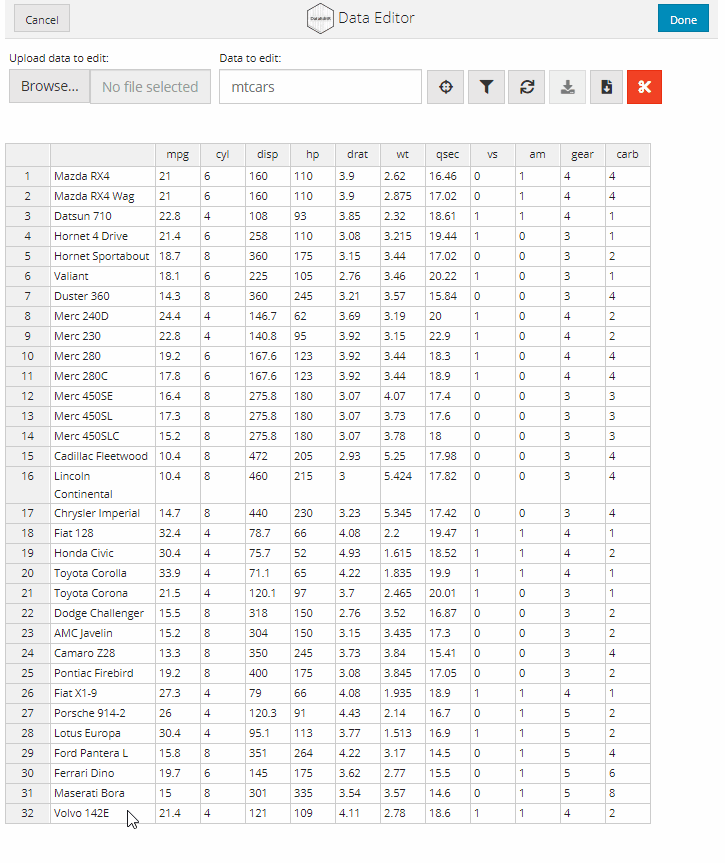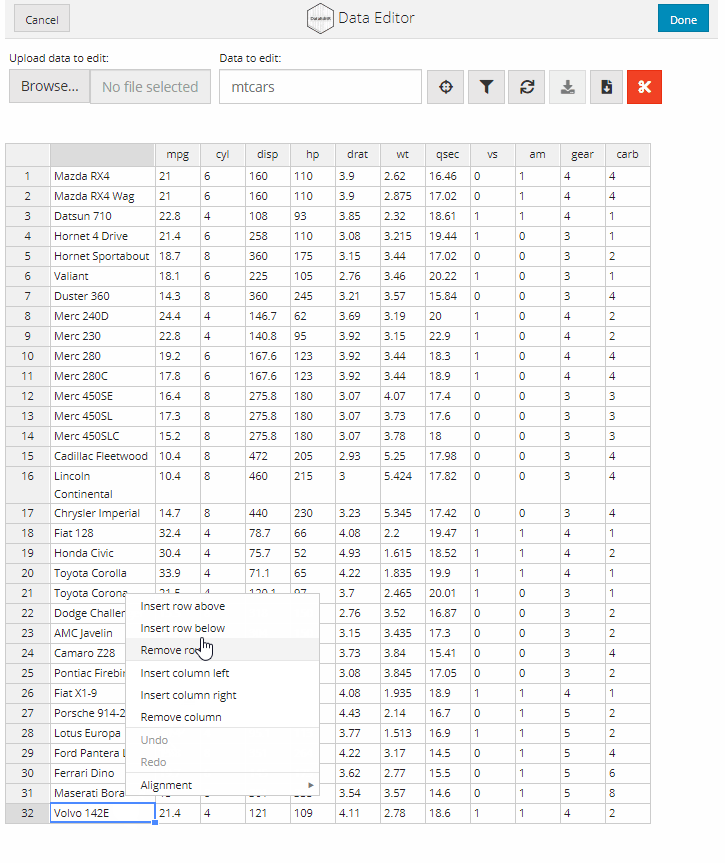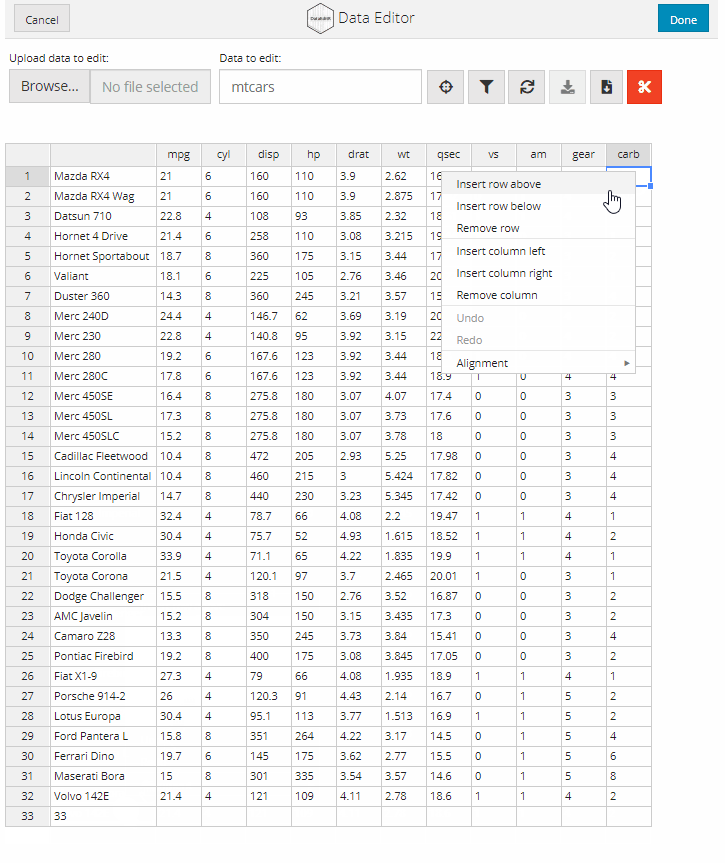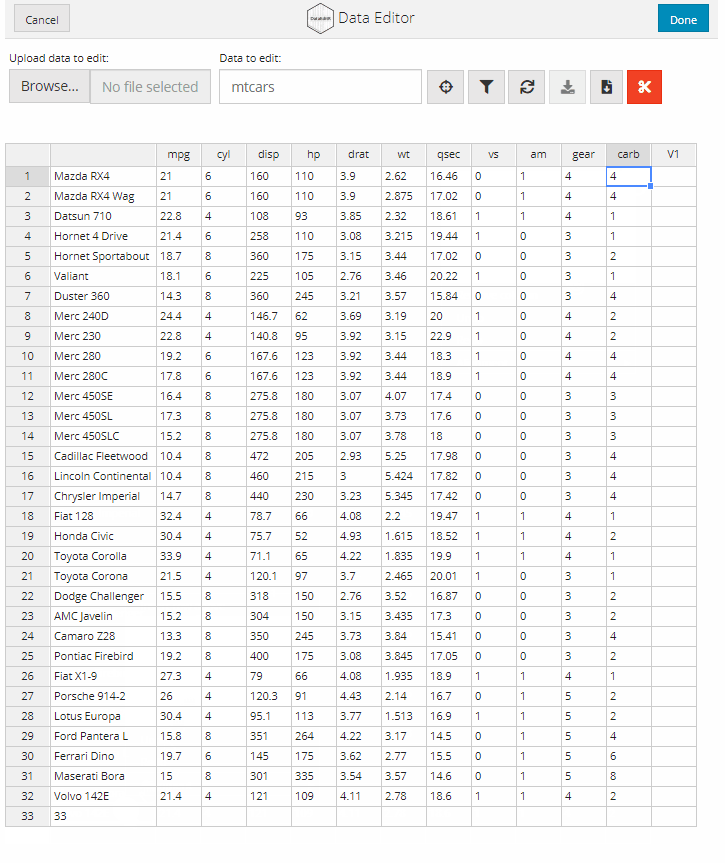























 الآن سوف نوضح طريقة حساب الإنحدار الخطي (linear regression) بإستخدام الدالة (
الآن سوف نوضح طريقة حساب الإنحدار الخطي (linear regression) بإستخدام الدالة (











 مثال آخر:
مثال آخر:





 خريطة الشارع المفتوحة (OpenStreetMap) والتي يرمز لها بالرمز (OSM) هي خريطة مفتوحة المصدر تم إطلاقها عام 2004 بواسطة ستيف كوست من المملكة المتحدة وهي عبارة عن مشروع تعاوني ويجمع بياناتها أكثر من مليون مستخدم مسجل وتدعم من خلال مؤسسة خريطة الشارع المفتوحة وهي مؤسسة غير ربحية. في هذا المقال سوف نعطي مقدمة عن آلية الإستفادة منها بواسطة لغة البرمجة آر R من خلال إتباع الخطوات التالية:
خريطة الشارع المفتوحة (OpenStreetMap) والتي يرمز لها بالرمز (OSM) هي خريطة مفتوحة المصدر تم إطلاقها عام 2004 بواسطة ستيف كوست من المملكة المتحدة وهي عبارة عن مشروع تعاوني ويجمع بياناتها أكثر من مليون مستخدم مسجل وتدعم من خلال مؤسسة خريطة الشارع المفتوحة وهي مؤسسة غير ربحية. في هذا المقال سوف نعطي مقدمة عن آلية الإستفادة منها بواسطة لغة البرمجة آر R من خلال إتباع الخطوات التالية:



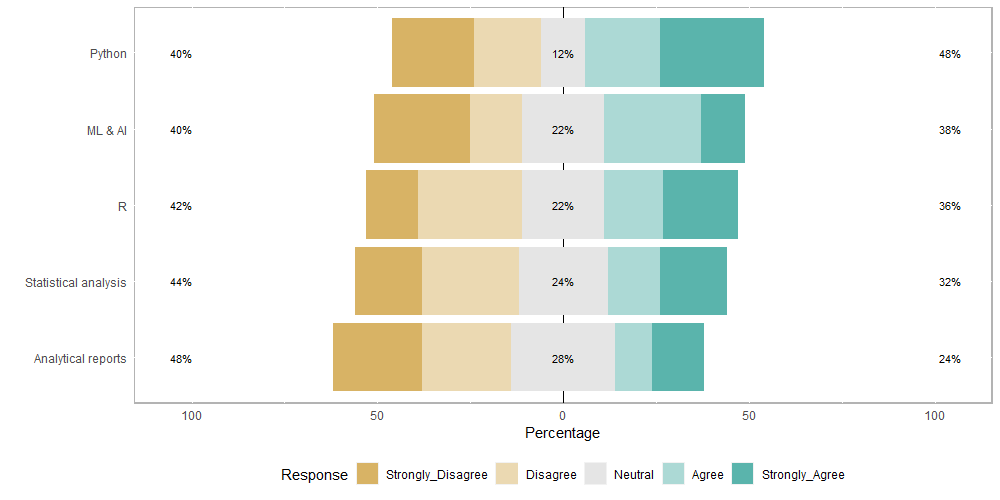

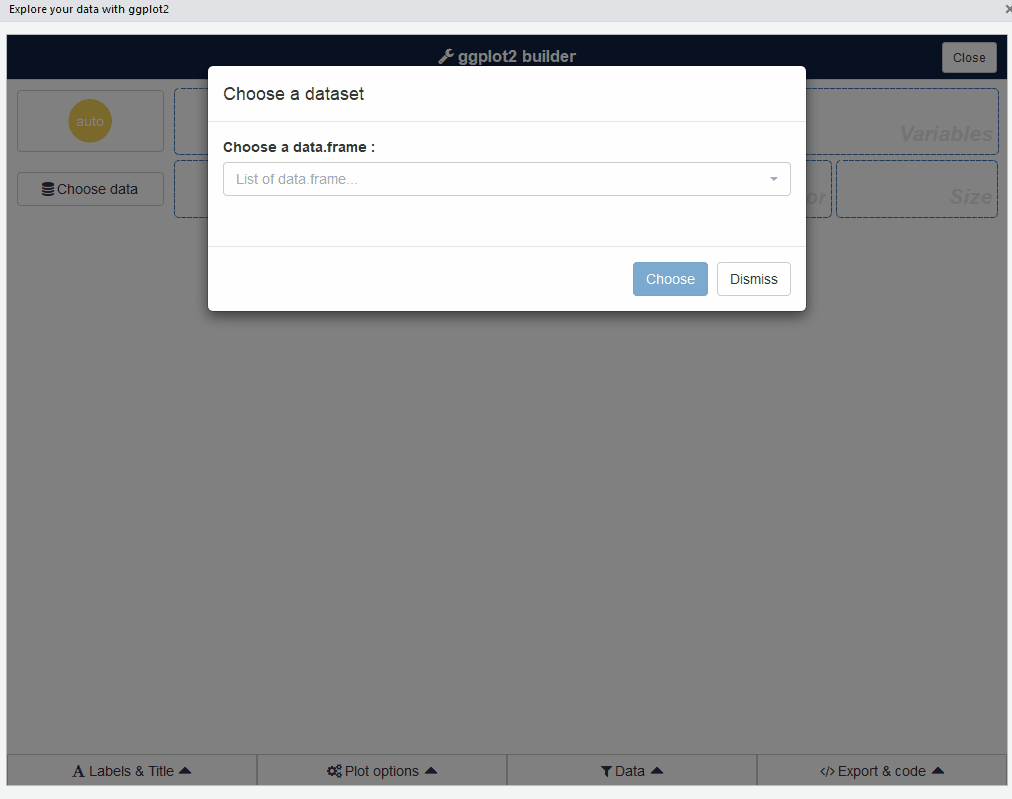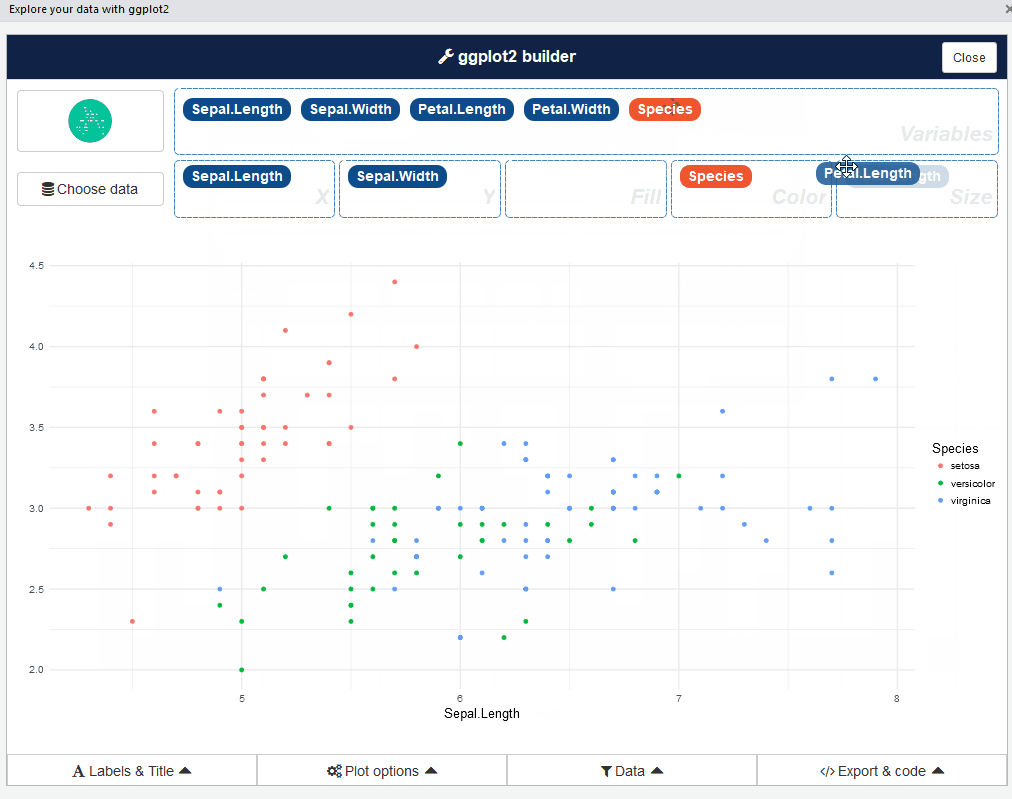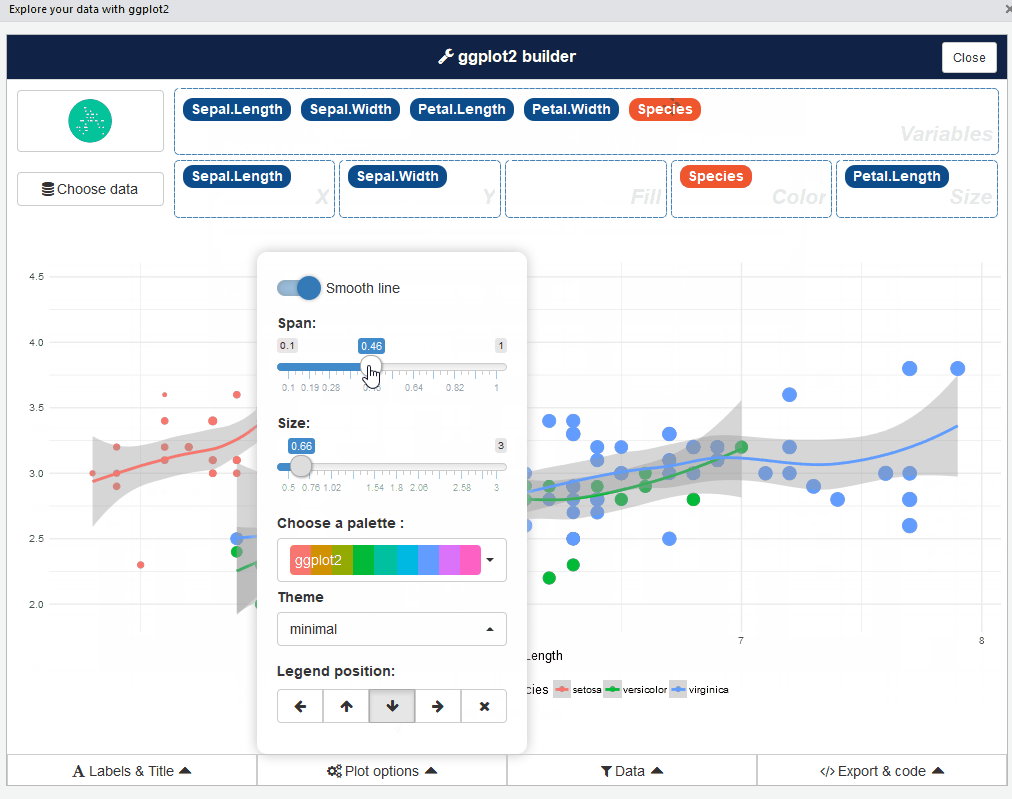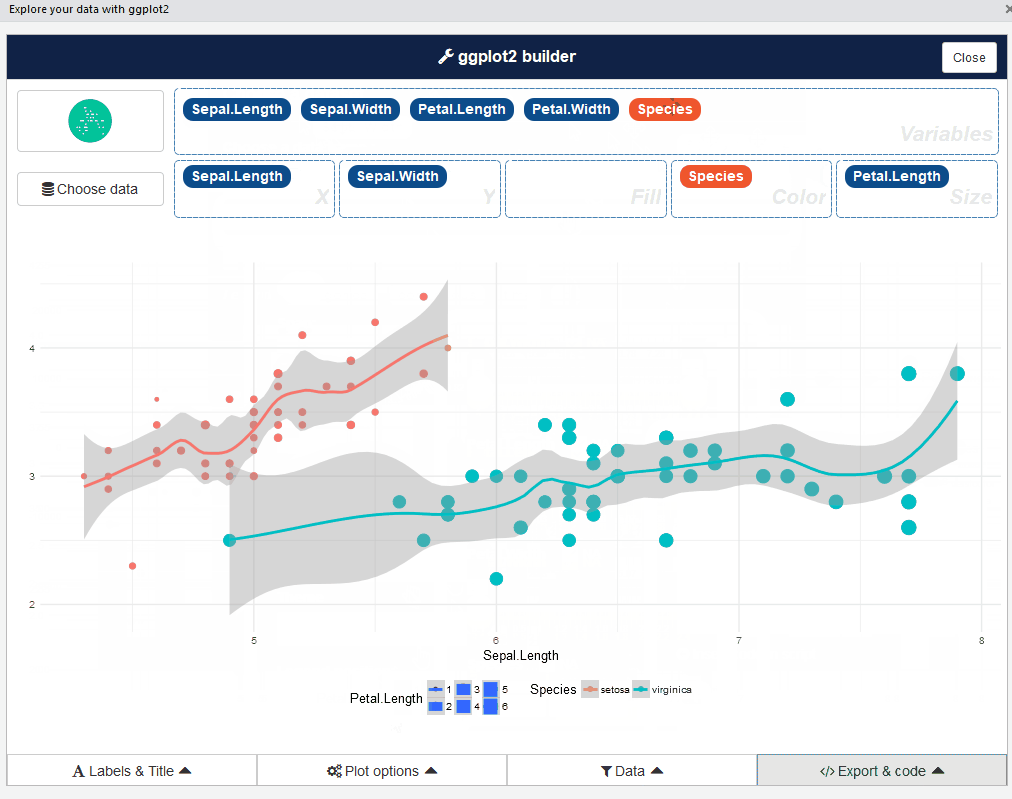

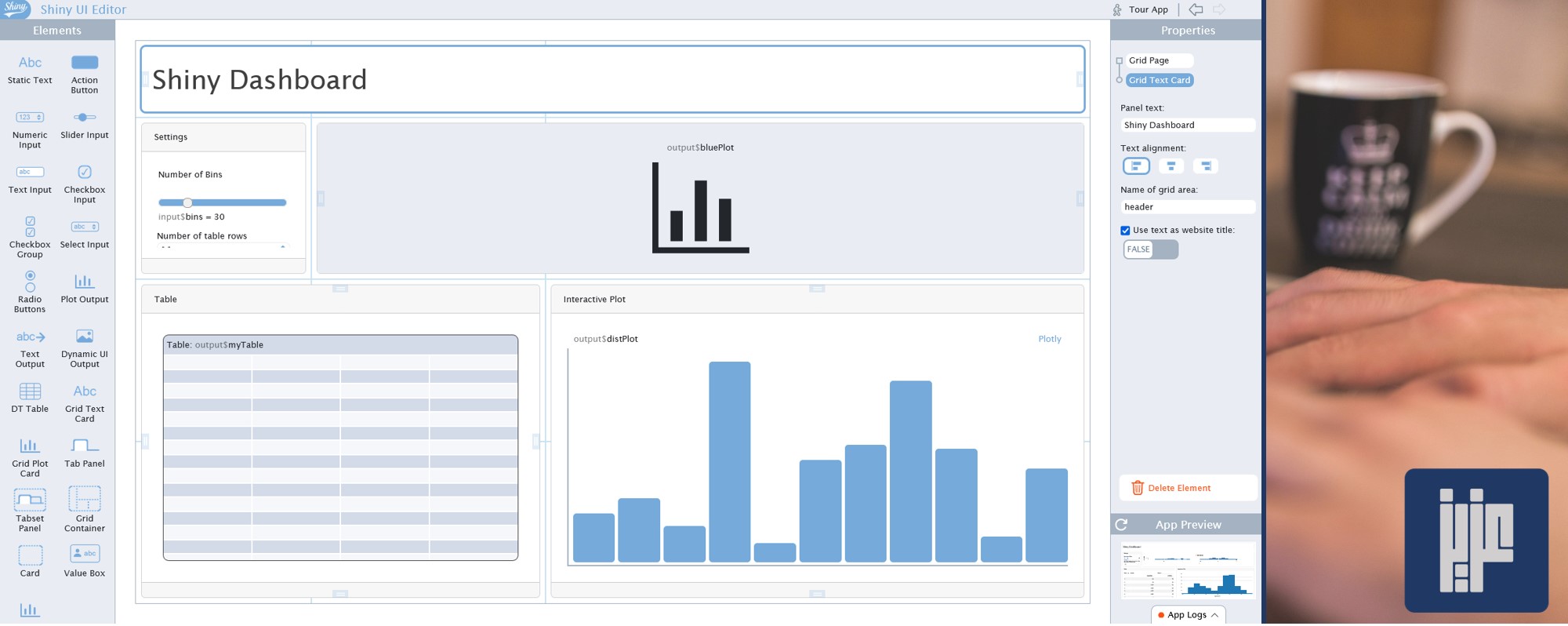
 بعد ذلك، يمكن الإنتقال للصفحة التالية:
بعد ذلك، يمكن الإنتقال للصفحة التالية: