
مكتبة (lida) هي مكتبة لتصوير البيانات من خلال استخدام تقنيات الذكاء الاصطناعي، حيث تتكامل مع عدد من نماذج اللغات الكبيرة (large language models) مثل (OpenAI, PaLM, Cohere, Huggingface) وكذلك مع مكتبات تصوير البيانات مثل (matplotlib, seaborn, altair, d3).
للبدء في استخدام مكتبة (lida) يمكن اتباع الخطوات التالية:
اولاً: تثبيت المكتبات المطلوبة
In:
pip install -U lida
اذا كنت تريد استخدام (lida) مع local huggingface models تحتاج تثبيت مكتبة (transformers) كما يلي:
In:
pip install lida[transformers]
ثانياً: تفعيل المكتبات المطلوبة
In:
from lida import Manager, TextGenerationConfig , llm
import seaborn as sns
ثالثاً: اعداد نموذج الذكاء الاصطناعي
سوف يتم استخدام نماذج الذكاء الاصطناعي من (openai) كما يلي:
In:
lida = Manager(text_gen = llm("openai", api_key="sk-proj-hFcR-0REuopxNZ-Dzj4aEUVQ2T7liZAvhUzWB_o"))
textgen_config = TextGenerationConfig(n=1, temperature=0.2, model="gpt-4o", use_cache=True)
library = "seaborn"
رابعاً: استيراد البيانات
البيانات التي سوف يتم تصويرها من خلال نماذج الذكاء الاصطتاعي هي:
In:
df = sns.load_dataset("healthexp")
print(df.head(3))
Out:
Year Country Spending_USD Life_Expectancy
0 1970 Germany 252.311 70.6
1 1970 France 192.143 72.2
2 1970 Great Britain 123.993 71.9
والتي يمكن تحميل نسخة منها من خلال الرابط.
خامساً: تلخيص البيانات، وتوليد الأهداف
In:
summary = lida.summarize(df, summary_method="default", textgen_config=textgen_config)
goals = lida.goals(summary, n=2, textgen_config=textgen_config)
for goal in goals:
print(goal)
Out:
Goal(question='How has the average spending in USD changed over the years for each country?', visualization="line chart with 'Year' on the x-axis, 'Spending_USD' on the y-axis, and lines colored by 'Country'", rationale="This visualization will help us understand the trend of spending over time for each country. By using 'Year' and 'Spending_USD' fields, we can identify patterns or anomalies in spending behavior across different countries.", index=0)
Goal(question='Is there a correlation between spending in USD and life expectancy across different countries?', visualization="scatter plot with 'Spending_USD' on the x-axis, 'Life_Expectancy' on the y-axis, and points colored by 'Country'", rationale="This scatter plot will allow us to visually inspect the relationship between spending and life expectancy. By plotting 'Spending_USD' against 'Life_Expectancy' and differentiating by 'Country', we can see if higher spending correlates with higher life expectancy and if this relationship varies by country.", index=1)
سادساً: تصوير االبيانات كما هو محدد في الأهداف
1. الهدف الأول
In:
i = 0
textgen_config = TextGenerationConfig(n=1, temperature=0.2, use_cache=True)
charts = lida.visualize(summary=summary, goal=goals[i], textgen_config=textgen_config, library=library)
charts[0]

2. الهدف الثاني
In:
i = 1
textgen_config = TextGenerationConfig(n=1, temperature=0.2, use_cache=True)
charts = lida.visualize(summary=summary, goal=goals[i], textgen_config=textgen_config, library=library)
charts[0]

ملاحظات هامة:
1. لإنشاء شكل بياني لتصوير البيانات من خلال استعلام المستخدم “user query” يمكن استخدام الكود:
In:
user_query = "what are the averages of spending across different countries?"
textgen_config = TextGenerationConfig(n=1, temperature=0.2, use_cache=True)
charts = lida.visualize(summary=summary, goal=user_query, textgen_config=textgen_config)
charts[0]

2. يمكن إعطاء النموذج بعض التعليمات، مثلاً تم طلب أن يكون عرض وارتفاع الشكل البياني متساوي وكذلك تغيير لونه الى الأحمر وترجمة الشكل البياني الى العربي مع مراعاة مشكلة عدم دعم بايثون للغة العربية وذلك كما يلي:
In:
code = charts[0].code
textgen_config = TextGenerationConfig(n=1, temperature=0.2, use_cache=True)
instructions = ["make the chart height and width equal", "change the color of the chart to red", "translate the chart to Arabic and solve Arabic not support issues"]
edited_charts = lida.edit(code=code, summary=summary, instructions=instructions, library=library, textgen_config=textgen_config)
edited_charts[0]

3. يمكن طلب شرح وتفسير الاشكال البيانية كما يلي:
In:
explanations = lida.explain(code=code, library=library, textgen_config=textgen_config)
for row in explanations[0]:
print(row["section"]," ** ", row["explanation"])
Out:
accessibility ** This section of the code is responsible for setting up the physical appearance of the chart. It creates a bar plot with a size of 10x6 inches, uses the 'viridis' color palette for the bars, and sets the x-axis and y-axis labels to 'Country' and 'Average Spending (USD)', respectively. The title of the chart is set to 'Average Spending Across Different Countries'. Additionally, the x-axis labels are rotated by 45 degrees for better readability, and the title is wrapped to fit within the plot area.
transformation ** This section of the code performs data transformation. It calculates the average spending for each country by grouping the data by the 'Country' column and then computing the mean of the 'Spending_USD' column. The result is reset to a new DataFrame called 'avg_spending', which contains the average spending values for each country.
visualization ** This section of the code adds annotations to the bar plot. It iterates over each bar in the plot and annotates it with the height value (average spending) formatted to two decimal places. The annotations are positioned at the center of each bar, slightly above the top, with a font size of 10. The 'xytext' and 'textcoords' parameters are used to adjust the position of the annotations.
4. يمكن طلب اقتراح او توصية بشكل بياني (Visualization Recommendation) كما يلي:
In:
textgen_config = TextGenerationConfig(n=2, temperature=0.2, use_cache=True)
recommended_charts = lida.recommend(code=code, summary=summary, n=2, textgen_config=textgen_config)
print(f"Recommended {len(recommended_charts)} charts")
for chart in recommended_charts:
display(chart)


5. يمكن المساهمة في تحديد الاهداف من خلال (persona) كما يلي:
In:
persona = "Analyzing life expectancy in US across years"
personal_goals = lida.goals(summary, n=2, persona=persona, textgen_config=textgen_config)
for goal in personal_goals:
print(goal)
Out:
Goal(question='How has life expectancy in the US changed over the years?', visualization="line chart of 'Year' vs 'Life_Expectancy'", rationale="By plotting 'Year' on the x-axis and 'Life_Expectancy' on the y-axis, we can observe trends and changes in life expectancy over time. This will help us understand whether life expectancy is improving, declining, or remaining stable in the US.", index=0)
Goal(question='Is there a correlation between healthcare spending and life expectancy in the US?', visualization="scatter plot of 'Spending_USD' vs 'Life_Expectancy'", rationale="By plotting 'Spending_USD' on the x-axis and 'Life_Expectancy' on the y-axis, we can examine the relationship between healthcare spending and life expectancy. This will help us determine if higher spending is associated with longer life expectancy, providing insights into the effectiveness of healthcare investments.", index=1)
































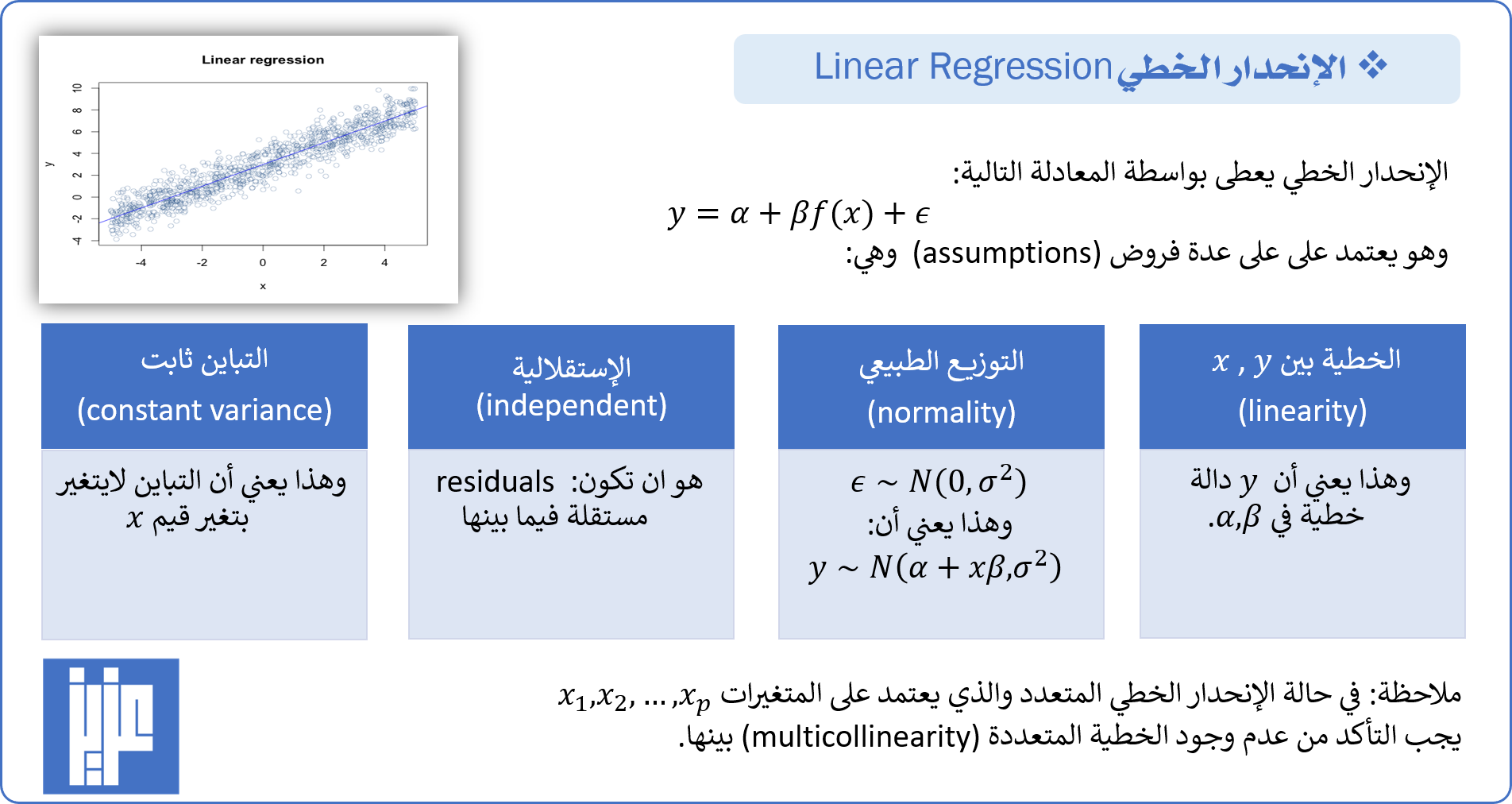
 ثم نقوم بنمذجة هذه العلاقة باستخدام الإنحدار الخطي كما يلي:
ثم نقوم بنمذجة هذه العلاقة باستخدام الإنحدار الخطي كما يلي: كما يمكن عرض ملخص نتائج هذا النموذج باستخدام الدالة:
كما يمكن عرض ملخص نتائج هذا النموذج باستخدام الدالة: ثانياً: Residuals vs Fitted values وهو مفيد للتأكد من فرض الخطية وتجانس التباين ( the assumption of linearity and homoscedasticity)، حيث يأخذ شكل إنتشار عشوائي حول الصفر والذي يمثل تقريباً منتصف المحور العامودي الذي يمثل البواقي الموجبة والسالبة. كذلك يجب أن لايكون هناك اي مشاهدة خارج الإنشار بشكل واضح (شاذة او متطرفة). والذي يمكن الحصول عليه باستخدام الكود:
ثانياً: Residuals vs Fitted values وهو مفيد للتأكد من فرض الخطية وتجانس التباين ( the assumption of linearity and homoscedasticity)، حيث يأخذ شكل إنتشار عشوائي حول الصفر والذي يمثل تقريباً منتصف المحور العامودي الذي يمثل البواقي الموجبة والسالبة. كذلك يجب أن لايكون هناك اي مشاهدة خارج الإنشار بشكل واضح (شاذة او متطرفة). والذي يمكن الحصول عليه باستخدام الكود: ثالثاً: Scale-Location وهو مفيد للتأكد من فرض تجانس التباين ( the assumption of homoscedasticity)، حيث يأخذ شكل إنتشار عشوائي ولا يأخد شكل منتظم متزايد او متناقص. والذي يمكن الحصول عليه باستخدام الكود:
ثالثاً: Scale-Location وهو مفيد للتأكد من فرض تجانس التباين ( the assumption of homoscedasticity)، حيث يأخذ شكل إنتشار عشوائي ولا يأخد شكل منتظم متزايد او متناقص. والذي يمكن الحصول عليه باستخدام الكود: رابعاً: Residuals vs Leverage
رابعاً: Residuals vs Leverage 












 مكتبة
مكتبة 
 ملاحظة: القيم المحددة في الكود أعلاه باللون الأحمر يمكن تغييرها وهي:
ملاحظة: القيم المحددة في الكود أعلاه باللون الأحمر يمكن تغييرها وهي:



 والتي يمكن تحميل نسخة منها من خلال
والتي يمكن تحميل نسخة منها من خلال 









{kind=link}